- ngmerge.plを利用して複数morogramデータを融合して出力したファイルは、以下のような形式になっているはずです。
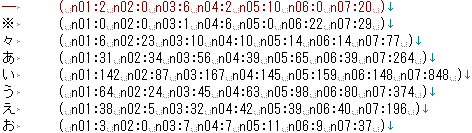
- 前のページでは、このデータを秀丸エディタを利用してじゃまな部分を削除し、Excelに渡すために必要な形式にする手順について説明しました。
- 毎回この作業をエディタを開いて手作業でやるのは非常に手間がかかります。
- そこで、perl・gawk等を使って加工用のマクロ或いはスクリプトを作成し、これを一度の作業でやってしまった方が効率的かつ万一の削除ミスも無いはずです。
- ここでは、perl用のスクリプトについて説明します。
- こに加えて、copyコマンドを利用した標題挿入や合体データの作成、batファイルを用いた半自動化の手順について説明します。
perlスクリプトで置換作業を半自動化
- perlは強力なテキスト加工能力を持ったscript言語です。
- perlについては、あちこちのWebサイトで解説されていますし、書籍も数多く出版されていますのでそれらを参照してください。
- ここでは、perl5.8用の極々単純な置換用スクリプトで上の作業を自動化してみましょう。
- perlのスクリプトはこんな形になります(人様に見せられるような代物ではないですが…)。
- #から始まる部分はコメント行になります。必要に応じて削除してください。
# ngmerge.pl の出力をExcelで読みやすく加工するためのscript
# perl5.6でこのスクリプトを動かす場合、以下の一行を入れる。
# perl5.8の場合は不要。
use utf8;
# 先頭から順に一行ずつ読み込み
while (<STDIN>) {
# ここから置換開始
# 各区切りの半角空白をタブに置換
tr/ /¥t/;
# 半角のパーレン(丸括弧)を削除
s/[()]//g;
# nの後ろに半角の数値が一つ以上続き、半角のセミコロンで終わるデータを削除
s/n[0-9]+://g;
# 連続する二つ以上のタブを一つにまとめる
s/¥t¥t+/¥t/g;
# 段落等の区切りとして段落先頭に■を入れてあるデータを対象にN-gram統計を取ってある場合、
# ■を含んだデータが不要な場合は、これを一行丸ごと削除する。
# もし■を含んだデータが必要ならば、この行の先頭に#を付けてコメントアウトする事
s/^.*■.+¥n//g;
# 最後尾の[タブ+改行]を[改行]のみに置換
s/¥t¥n/¥n/g;
# 加工済みの行を出力
print;
}
# perl5.6でこのスクリプトを動かす場合、以下の一行を入れる。
# perl5.8の場合は不要。
use utf8;
# 先頭から順に一行ずつ読み込み
while (<STDIN>) {
# ここから置換開始
# 各区切りの半角空白をタブに置換
tr/ /¥t/;
# 半角のパーレン(丸括弧)を削除
s/[()]//g;
# nの後ろに半角の数値が一つ以上続き、半角のセミコロンで終わるデータを削除
s/n[0-9]+://g;
# 連続する二つ以上のタブを一つにまとめる
s/¥t¥t+/¥t/g;
# 段落等の区切りとして段落先頭に■を入れてあるデータを対象にN-gram統計を取ってある場合、
# ■を含んだデータが不要な場合は、これを一行丸ごと削除する。
# もし■を含んだデータが必要ならば、この行の先頭に#を付けてコメントアウトする事
s/^.*■.+¥n//g;
# 最後尾の[タブ+改行]を[改行]のみに置換
s/¥t¥n/¥n/g;
# 加工済みの行を出力
print;
}
- スクリプトの名前は何でもよいのですが、[kakou.pl]としておきました。
- スクリプトはここからダウンロードする事も可能です。
- ダウンロードしたスクリプトを、ngmerge.plで融合したデータがあるフォルダに置いておきます。
- 実行方法は以下の通りです。
perl kakou.pl < [ngmerge.plで融合したテキスト] > [加工後のテキスト]
- コマンドプロンプト上で実行すると、こんな感じです。
- D:¥temp¥morogram¥にデータがあると仮定しています。
- ngmerge.plで融合したテキストを[ngmerge.txt]、加工したテキストを[kakou.txt]としています。
C:¥ コマンドプロンプト
C:¥D:
D:¥>cd temp¥morogram
D:¥temp¥morogram>perl kakou.pl < ngmerge.txt > kakou.txt- 加工後の結果です。

copyコマンドを使って標題を挿入
- 秀丸で置換、或いは上記のkakou.plで加工したデータをExcelに貼り付けて利用する場合、先頭行に項目名がないと何かと不便です。
- Excelで項目名を補ってもよいのですが、これもDOSのコピーコマンドを利用すれば簡単に標題を挿入する事が可能です。
- あらかじめ、標題を記入したテキストファイルを用意しておきます。
- ここではファイル名を[hyoudai.txt]にしておきました。
- 各標題の間は必タブ区切りにし、最後を改行しておくのを忘れないでください。
- また、ファイルは必ず文字コードにutf-8を指定して保存しておきましょう。
文字列 牛人 狐憑 中島敦
名人伝 文字禍 山月記
- 次に、コマンドプロンプトを起動し、以下のように入力してください。
- D:¥temp¥morogram¥にデータがあると仮定しています。
- 上の手順で加工したテキストを[kakou.txt]、最終的に出力されるテキストを[kekka.txt]としています。
C:¥ コマンドプロンプト
C:¥D:
D:¥>cd temp¥morogram
D:¥temp¥morogram>copy /Y /B /V hyoudai.txt + kakou.txt kekka.txt- これは、copyコマンドで、[hyoudai.txt]の後ろに[kakou.txt]をくっつけ、それを[kekka.txt]として出力するという命令文です。
- オプションは「ファイルの上書き時に確認のメッセージを表示しない[/Y]」「バイナリ形式のファイル[/B]」 「コピー先のファイルが正しく書き込まれたか[/V]」をそれぞれ意味します。
- テキストファイルなのにもかかわらずバイナリ形式の指定をするのは、扱っているテキストファイルがutf-8形式のためです。
- 通常、コマンドプロンプトで使用可能な文字はShift-JISです。
- 加工後の結果です。最上行に標題が挿入されています。
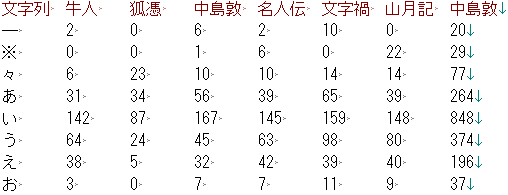
batファイルで手順を半自動化
- 以上の手順も、batファイルを作成しておけば、作業を半自動化する事が可能です。
- ここでは、[batファイルを作ろう]で作成したバッチファイルを下敷きに、kakou.plでNGSMを加工し、copyコマンドで標題部分を挿入する命令batファイルを作成してみました。
- 仮にファイル名を[n-gram.bat]にしておきました。拡張子が[bat]ならばファイル名は何でも構いません。
- remから始まる部分はコメント行になります。必要に応じて削除してください。
rem morogramでN-gramモデルを構築→ngmerge.plに渡すために加工。
morogram-0.7.1w.exe --p --f=1 --g=1,1 gyujin.txt > m01.txt
sortl -W U -t ¥t +1 -o n01.txt m01.txt
morogram-0.7.1w.exe --p --f=1 --g=1,1 kitsunetsuki.txt > m02.txt
sortl -W U -t ¥t +1 -o n02.txt m02.txt
morogram-0.7.1w.exe --p --f=1 --g=1,1 kouhuku.txt > m03.txt
sortl -W U -t ¥t +1 -o n03.txt m03.txt
morogram-0.7.1w.exe --p --f=1 --g=1,1 meijinden.txt > m04.txt
sortl -W U -t ¥t +1 -o n04.txt m04.txt
morogram-0.7.1w.exe --p --f=1 --g=1,1 mojika.txt > m05.txt
sortl -W U -t ¥t +1 -o n05.txt m05.txt
morogram-0.7.1w.exe --p --f=1 --g=1,1 sangetsuki.txt > m06.txt
sortl -W U -t ¥t +1 -o n06.txt m06.txt
morogram-0.7.1w.exe --p --f=1 --g=1,1 nakajima.txt > m07.txt
sortl -W U -t ¥t +1 -o n07.txt m07.txt
rem ngmerge.plでNGSMモデルを構築。
perl ngmerge.pl n01.txt n02.txt n03.txt n04.txt n05.txt n06.txt n07.txt > m0kekka.txt
rem kakou.plでNGSMデータを加工。
perl kakou.pl < m0kekka.txt > n0kekka.txt
rem 標題を最上行に挿入。最終データを[nakajima.txt]として出力。
copy /Y /B /V hyoudai.txt + n01kekka.txt nakajima.txt
morogram-0.7.1w.exe --p --f=1 --g=1,1 gyujin.txt > m01.txt
sortl -W U -t ¥t +1 -o n01.txt m01.txt
morogram-0.7.1w.exe --p --f=1 --g=1,1 kitsunetsuki.txt > m02.txt
sortl -W U -t ¥t +1 -o n02.txt m02.txt
morogram-0.7.1w.exe --p --f=1 --g=1,1 kouhuku.txt > m03.txt
sortl -W U -t ¥t +1 -o n03.txt m03.txt
morogram-0.7.1w.exe --p --f=1 --g=1,1 meijinden.txt > m04.txt
sortl -W U -t ¥t +1 -o n04.txt m04.txt
morogram-0.7.1w.exe --p --f=1 --g=1,1 mojika.txt > m05.txt
sortl -W U -t ¥t +1 -o n05.txt m05.txt
morogram-0.7.1w.exe --p --f=1 --g=1,1 sangetsuki.txt > m06.txt
sortl -W U -t ¥t +1 -o n06.txt m06.txt
morogram-0.7.1w.exe --p --f=1 --g=1,1 nakajima.txt > m07.txt
sortl -W U -t ¥t +1 -o n07.txt m07.txt
rem ngmerge.plでNGSMモデルを構築。
perl ngmerge.pl n01.txt n02.txt n03.txt n04.txt n05.txt n06.txt n07.txt > m0kekka.txt
rem kakou.plでNGSMデータを加工。
perl kakou.pl < m0kekka.txt > n0kekka.txt
rem 標題を最上行に挿入。最終データを[nakajima.txt]として出力。
copy /Y /B /V hyoudai.txt + n01kekka.txt nakajima.txt
batファイルは使い回そう
- batファイルを一つ作成したら、それをテンプレートファイルとして取っておきましょう。
- そうすれば、次から[N-gramモデル構築]→[NGSMデータ構築]→[NGSMデータ加工]→[その他の加工]の手順をこのテンプレートファイルを書き換えるだけで簡単に実行できます。
- ファイル名も、あらかじめ数値で構成された番号にしておくと、対象となるテキストの増減に応じて番号を適宜変更すれば済みますので便利かと思います。
- その際は、別途テキストの番号とデータ名とが対応したファイルを作成しておかないと、後でデータ整理の時に迷う可能性が大です。
- このファイルを、上のcopyコマンドで標題として利用できる形式にして、batファイル実行の手順でその過程を組み込んでおくのもよいでしょう。
- 後で統計処理する際には、別途全てのデータを合わせたデータを作っておきましょう。
- このデータは、あらかじめエディタなどでテキストを合体させてもよいですが、copyコマンドを利用して合体させる事も可能です。
- 但し、データ全体を対象にN-gramモデルを構築すると、各データファイルに跨った共起頻度を集計しますので、結果的に間違った結果が生成されます。
- そのため、必ずデータ間に任意の区切り文字を入れておいて、後で採集データから区切り文字を含む部分を削除しておくようにしましょう。
- それらも含んだbatファイルを提示しておきます。
- remから始まる部分はコメント行になります。必要に応じて削除してください。
- ここでは、仮にファイル名を[n-gram2.bat]にしておきました。拡張子が[bat]ならばファイル名は何でも構いません。
rem 全てのデータを合体する。合体したファイル名を[00.txt]として保存。
rem このファイル名にしておけば、対象データが増減しても、合体ファイル名を変更する必要が無い。
copy /Y /B /V 01.txt + 02.txt + 03.txt + 04.txt + 05.txt + 06.txt 00.txt
rem morogramでN-gramモデルを構築→ngmerge.plに渡すために加工する。
morogram-0.7.1w.exe --p --f=1 --g=1,1 00.txt > m00.txt
sortl -W U -t ¥t +1 -o n00.txt m00.txt
morogram-0.7.1w.exe --p --f=1 --g=1,1 01.txt > m01.txt
sortl -W U -t ¥t +1 -o n01.txt m01.txt
morogram-0.7.1w.exe --p --f=1 --g=1,1 02.txt > m02.txt
sortl -W U -t ¥t +1 -o n02.txt m02.txt
morogram-0.7.1w.exe --p --f=1 --g=1,1 03.txt > m03.txt
sortl -W U -t ¥t +1 -o n03.txt m03.txt
morogram-0.7.1w.exe --p --f=1 --g=1,1 04.txt > m04.txt
sortl -W U -t ¥t +1 -o n04.txt m04.txt
morogram-0.7.1w.exe --p --f=1 --g=1,1 05.txt > m05.txt
sortl -W U -t ¥t +1 -o n05.txt m05.txt
morogram-0.7.1w.exe --p --f=1 --g=1,1 06.txt > m06.txt
sortl -W U -t ¥t +1 -o n06.txt m06.txt
rem ngmerge.plでNGSMモデルを構築。
perl ngmerge.pl n01.txt n02.txt n03.txt n04.txt n05.txt n06.txt n00.txt > m0kekka.txt
rem kakou.plでNGSMデータを加工。
perl kakou.pl < m0kekka.txt > n0kekka.txt
rem 合体データの共起頻度上位順に並び替え(これは必要に応じて入れる)
sortl -W U -n -r -t ¥t +7 -o n01kekka.txt n0kekka.txt
rem 標題を最上行に挿入。最終データを[kekka.txt]として出力。
copy /Y /B /V hyoudai.txt + n01kekka.txt kekka.txt
rem 作業仮定で作成したファイルを削除
del n0*.txt
del m0*.txt
rem このファイル名にしておけば、対象データが増減しても、合体ファイル名を変更する必要が無い。
copy /Y /B /V 01.txt + 02.txt + 03.txt + 04.txt + 05.txt + 06.txt 00.txt
rem morogramでN-gramモデルを構築→ngmerge.plに渡すために加工する。
morogram-0.7.1w.exe --p --f=1 --g=1,1 00.txt > m00.txt
sortl -W U -t ¥t +1 -o n00.txt m00.txt
morogram-0.7.1w.exe --p --f=1 --g=1,1 01.txt > m01.txt
sortl -W U -t ¥t +1 -o n01.txt m01.txt
morogram-0.7.1w.exe --p --f=1 --g=1,1 02.txt > m02.txt
sortl -W U -t ¥t +1 -o n02.txt m02.txt
morogram-0.7.1w.exe --p --f=1 --g=1,1 03.txt > m03.txt
sortl -W U -t ¥t +1 -o n03.txt m03.txt
morogram-0.7.1w.exe --p --f=1 --g=1,1 04.txt > m04.txt
sortl -W U -t ¥t +1 -o n04.txt m04.txt
morogram-0.7.1w.exe --p --f=1 --g=1,1 05.txt > m05.txt
sortl -W U -t ¥t +1 -o n05.txt m05.txt
morogram-0.7.1w.exe --p --f=1 --g=1,1 06.txt > m06.txt
sortl -W U -t ¥t +1 -o n06.txt m06.txt
rem ngmerge.plでNGSMモデルを構築。
perl ngmerge.pl n01.txt n02.txt n03.txt n04.txt n05.txt n06.txt n00.txt > m0kekka.txt
rem kakou.plでNGSMデータを加工。
perl kakou.pl < m0kekka.txt > n0kekka.txt
rem 合体データの共起頻度上位順に並び替え(これは必要に応じて入れる)
sortl -W U -n -r -t ¥t +7 -o n01kekka.txt n0kekka.txt
rem 標題を最上行に挿入。最終データを[kekka.txt]として出力。
copy /Y /B /V hyoudai.txt + n01kekka.txt kekka.txt
rem 作業仮定で作成したファイルを削除
del n0*.txt
del m0*.txt