- ngmerge.plを利用して複数morogramデータを融合して出力したファイルは、以下のような形式になっているはずです。
- このデータから、テキストの分析をする事も可能ですが、Excel等を使って統計的観点から分析するためには、不必要な部分があるのも事実です。
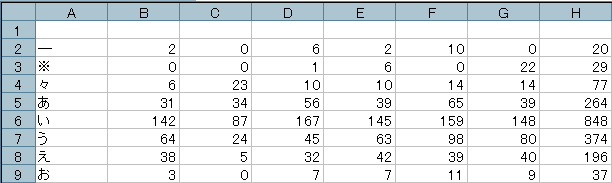
- 例えば、上図のNGSMモデルは、中島敦の幾つかの作品の中から読点及びその直前の一文字を対象に[1-gram・頻度1以上]でN-gram統計をとり、ngmerge.plで融合したものです。
- これをExcelに渡して簡単な統計処理をしようとした場合、そこには幾つかの問題が存在します。
- 読点直前の文字を対象に分析したい場合は、読点のN-gram統計を取る必要はない。
- これは、一行目を削除するか、初めからmorogramで[句読点を削除]するというオプションを利用して、読点をN-gram統計の対象としない設定にしておけば解決します。
- NGSMモデルの数値部分だけ必要とする場合、ファイル名や括弧の部分がじゃまである。
- この場合、秀丸等のエディタの正規表現や簡単なperl scriptを利用してじゃまな部分を削除しておきましょう。
- 但し、一端ファイル名を削除してしまうので、必ずファイルの並び順を記憶しておく必要があります。
- NGSMモデルを作成する前に、あらかじめファイルの並び順を明記したデータファイルを作成しておきましょう。
- batファイルでngmerge.plを利用している場合は、batファイル中のngmerge.pl実行部分に書かれているファイルの並び方を利用すればよいでしょう。
- Excelとの関連
- Excelにデータを渡す場合には、桁区切りを統一しておいた方がよいでしょう。
- NGSMモデルでは、半角空白と水平タブとの両方が区切り文字に利用されています。
- 半角空白を水平タブに置換し、二つ以上の水平タブも一つにまとめてしまいましょう。
- Excelはutf-8テキストファイルの読み込みに対応していません。
- 秀丸等のエディタで加工したNGSMを開き、全文選択してコピー→Excelに貼り付けましょう。
- 以下、秀丸を事例に、EXcelに渡すためのNGSMファイルの加工と、Excelへのデータコピーの方法について説明します。
秀丸で加工する
- NGSMデータを秀丸で加工します。
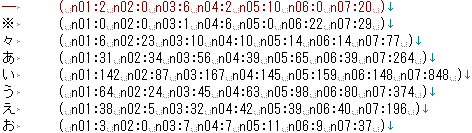
- ここでは、ファイル名を[n+0で始まる二桁の数値]に統一してあります。
- 初めに、読点の行があれば、その行を削除しましょう。
- 次に、置換コマンドの正規表現を利用して、半角空白を水平タブ(\n)に置き換えます。

- 半角のパーレンを削除します。
- 検索用キーワードにを、置換用キーワードには何も指定しないでください。
- は、[半角のパーレン左右どちらか一文字]という意味の正規表現です。
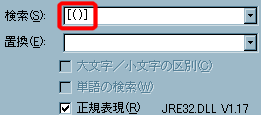
- 置換を実行した結果です。

- ファイル名をを削除します。
- 検索用キーワードにを、置換用キーワードにはを指定してください。
- は、[水平タブ]+[半角のコロン一文字以外の任意の一文字以上]+[半角のコロン]という意味の正規表現です。
- それを[水平タブ]に置換します。
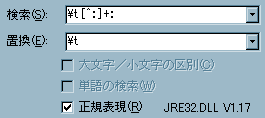
- 置換を実行した結果です。
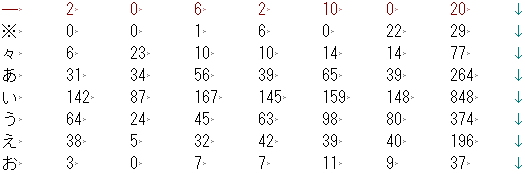
- 行末の[水平タブ][改行]の部分がじゃまですが、この部分はExcelに貼り付けた際に自動的に消えますので、放っておいても大丈夫です。
- もし、気になるようであれば、[水平タブ]+[改行]という正規表現を検索用キーワードに入力し、それを[改行]に置換してください。
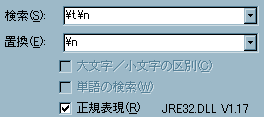
- 置換を実行した結果です。

- これで、秀丸でのテキスト加工が出来上がりました。必ず上書き保存しておきましょう。
Excelへコピー
- 上の項目で加工したNGSMデータを、Excelに貼り付けましょう。
- 先に述べたように、Excelはutf-8テキストファイルの直接読み込みに対応していません。
- 従って、utf-8のテキストデータをExcelで利用するには、一端該当ファイルを秀丸で開き、データを全選択してコピーし、Excelに貼り付け る必要があります。
- 先ほど加工したNGSMファイルを開きます。
- メニューの[編集]→[全てを選択]を選択します。
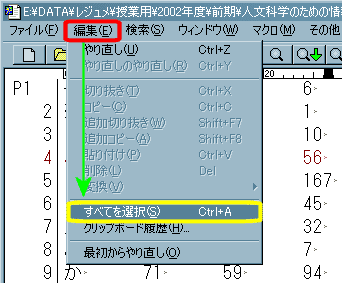
- テキスト全文が選択されます。

- 選択後、メニューの[編集]→[コピー]を選択します。
- コピーを実行したら、Excelを起動します。
- A2セルをアクティブにして、メニューの[編集]→[貼り付け]を選択します。
- 別にA1でもよいのですが、後で1行目に各項目を入力したいので、ここではA2を指定してあります。
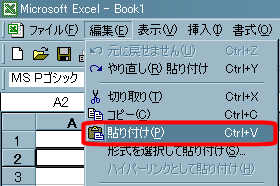
- 貼り付けが実行されます。
- 貼り付け後、任意のセルを左クリックするか、[Enter]キーを押しせば完了です。