- morogramの出力結果は、gram数毎の頻度順に整理されています。
- これを、単純に頻度順、或いは文字コード順に並べ替えたい場合には、並べ替え専用のソフトウェアを使う必要があります。
- ここでは、utf-8対応のsortlを利用してみましょう。
sortlとは?
- sortlは、益山健氏の開発にかかる、並べ替え(ソート)専用のWindows用プログラムです。
- このプログラムはコマンドプロンプト上で動作します。
- 特徴として、以下の事が挙げられます。
- 日本語用の文字コード以外にも、中国語やUnicode(utf-8やutf-16)にも対応しています。
- 豊富なオプションが指定可能。
- 動作がそこそこ軽い。
- Excelでも並べ替えは可能ですが、Excelには並べ替えるデータ件数の上限が65536という制限があります。しかもそこまでデータを並べると、間違いなくExcelの動作が不安定になります。
- それに比べたら、sortlの動作は並べ替え専用のプログラムという事もあり、遙かに動作が軽く出来ています。
sortlを利用可能にする
- sortlは上記益山氏のWebサイトにて公開されています。
- 公開されているファイルは、zip形式でアーカイブ&圧縮されていますので、まず解凍してから適当なフォルダにコピーします。
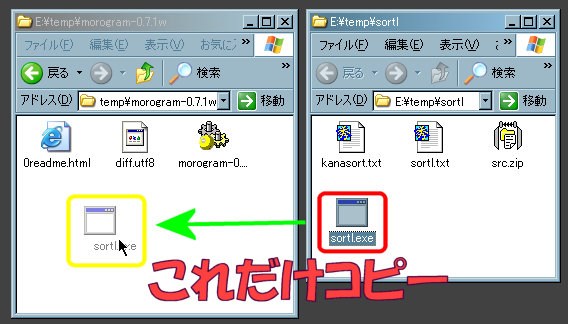
- morogramと一緒に使う事を前提にするならば、解凍後生成されたファイルの中から、[sortl.exe]のみをオリジナル版morogram、もしくは実行ファイル版morogramがあるフォルダにコピーすればよいでしょう。
- 次に、コマンドプロンプトを実行します。
- [スタートメニュー]→[プログラム]→[コマンドプロンプト]を選択してコマンドプロンプトを実行します。
- コマンドプロンプトが表示されたら、morogramの実行ファイルのあるフォルダに移動します。
- 以下の画面に従って入力してください。
C:\ コマンドプロンプト
C:\D:
D:\>cd temp\morogram
D:\temp\morogram>- これで、morogramのあるフォルダに移動しました。
- ここで、sortl.exe -help と入力して[Enter]キーを押します。
- 以下の画面のようなメッセージが表示されていたら、sortlを実行可能です。
C:\ コマンドプロンプト
D:\temp\morogram>sortl.exe -help
usage: sortl [-bdfiKMnr][-cmu][-o file][-t/T S][-R S][-W CS][flds] file ...
b=trim blanks, d=alphanumeric only, f=case fold, i=ignore non-printable
K=kana, M=month, n=number, r=reverse
c=check sorted, m=merge only, u=unique
o=output file, t/T=field separator, R=record separator, W=encoding
CS = Utf|Sjis|Big5|Euc|Tw-euc|Narrow
flds = -k fld1[.char1][opt1][,fld2[.char2][opt2]]
+fld1[.char1][opt1] [-fld2[.char2][opt2]]
=fld[.char][opt]
opts1, opts2 = bdfiKMnr sortlでmorogramの出力ファイルを並べ替える
- sortlを実行したいファイルは、必ずsortlと同じフォルダに置いてください。
- sortlには多くのオプションがありますが、morogramの出力結果を並び替える場合は、以下の書式に従って入力してください。
gram数を基準に大きい数字から順に並べ替え
sortl -W U -n -r -t \t +2 -o [出力ファイル] [入力ファイル]
頻度数を基準に大きい数字から順に並べ替え
sortl -W U -n -r -t \t +0 -o [出力ファイル] [入力ファイル]
文字コードを基準にコード番号が若い順に並べ替え
sortl -W U -t \t +1 -o [出力ファイル] [入力ファイル]
- 後述のngmerge.plで複数テキストを融合する場合は、この書式で並び替えます。
- これらの書式のオプションのうち、以下に挙げる部分はこのような意味をなします。
| オプション | 説明 |
|---|---|
| -W U | 文字コードにutf-8を利用しているという宣言をしています。 |
| -n | 数字順に並び替えるという意味です。 |
| -r | 数値を逆順(数値の大きいのものから順に)で並べ替えるという意味です。 |
| -o | 出力ファイルを指定します。 morogramとは異なって、[出力ファイル][入力ファイル]の順である事に注意しましょう。 |
| -t \t | 並べ替える各項目の区切りが、水平タブである事を示します。 |
| +[数値] | 頻度数、文字列、gram数の項目を指定します。 |
- morogramの出力結果は、一行ごとに以下の形式に従っています。
頻度[水平タブ]文字列[水平タブ]gram数
- 区切り文字に[水平タブ]を指定しますので、一行ごとに三つの部分に分かれるのが解るかと思います。
- この三つは、左から順に \0(頻度) \1(文字列) \2(gram数) と分類されます。
- この項目を複数組み合わせることも可能です。
各gram数毎に、頻度上位順で並べ替え
sortl -W U -n -r -t \t +2 +0 -o [出力ファイル] [入力ファイル]
頻度上位順で並び替え、同頻度中の文字列を並び替え
sortl -W U -n -r -t \t +0 +1 -o [出力ファイル] [入力ファイル]
- コマンドプロンプトを終了するには、「exit」と入力して[Enter]キーを押してください。