見えない・読めない電子テキスト
前のページでは、電子テキストの特徴を挙げました。
しかし、デジタルテキストにはそのメリット故に欠点もあります。
その一番大きなものとして、デジタルテキストは「そのままでは見えない・読めない」ことです。
紙やその他(木・布・石など)の媒体に載せられた文字とテキストは、そのままで人間の目で確認することが可能です。点字などでも同じです(人間の目、或いは触感として確認できます)。無論、それを何らかの情報が載せられた文字として認識するためには、その文字がどの言語体系に属しているか、またその体系を使いこなせるかが必要になります。
しかし、半導体やその他のメディア(光ディスク・ハードディスク)、あるいはインターネット上を流れているデジタルデータとしての電子テキストは、そのままの状態で人間の目で確認することはできません。当然、そこから何らかの情報を人間の感覚で知ることはできません。そのため、デジタルデータが媒体に収録されているのみの状態では、それを文字として認識することは不可能となります。
デジタルテキストをテキストとして認識するためには、以下の要素が必要となります。
- デジタルテキストの記録方式に対応し、情報が載せられている媒体を読むことが可能なハードウェア(パソコンなど)とソフトウェア(オペレーティングシステム)の用意
- ハードウェアとソフトウェアによって読み込まれ、解釈された情報を表示するためのハードウェア(モニター)
- 情報表示ハードウェア上で文字を表示するためのソフトウェア(アプリケーションソフト・フォント)
このように、デジタルテキストを見るだけでも必要なハードルは多岐にわたります。便利な反面、それを使うためのハードルが高いのもデジタルテキスト(を初めとするデジタル情報)の特徴とも言えるでしょう。
電子テキストは一次元の存在
コンピュータの内部では、電子テキストは全て前から順に詰め込まれているだけのデータにしか過ぎません。
そのため、ある程度レイアウトを固定しようとしたい場合は、余計な情報を入れる必要があります。下の例で説明しましょう。
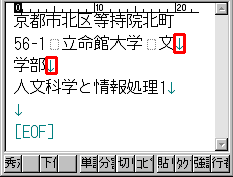
プレーンなテキストデータです。↓で改行されています。後は折り返し表示になっています。
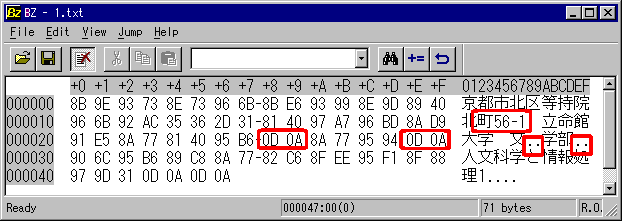
上記データをバイナリエディタBZ(c.mos氏作成 http://www.zob.ne.jp/~c.mos/soft/bz.htmlで公開)で閲覧したものです。
「北町56-1」「文学部」が折り返しているように見えますが、前者は単なる折り返し、後者は「制御記号の改行」を挟んで二行に跨っています。
0028-0029、002E-002F、0043-0044、0045-0046のデータの中にある「0D0A」が「改行をする」という命令 (制御記号)になります。
「等持院北町56-1」は「文字列通りの」一続きのデータで、対して「文学部」は「文」「改行」「学」という一続きのデータになります。従って、コンピュータ的には「文学」として認識されません。
総体としては、0000-0044までの「一続きのデータ」になります。電子テキストは「一本のテープに前から順に書かれた一続きのデータ」と喩えることができるでしょう。
電子テキストは、制御記号やソフトウェアによって複雑なレイアウトに見せているだけです。実際には一次元上に配列されたデータの総体であるにしか過ぎないのです。これをまず覚えておきましょう。
テキストデータで何が表現でき、表現できないか?
テキストデータは、文字情報だけで構築されており、しかもその配列は一次元上という制約があります。
そのため、レイアウトの構造や特殊な文字情報は反映されません。

『呂氏春秋』有始覧 務本篇冒頭(『四部叢刊初編』より)
上は版本の画像、下はそれをテキストデータに起こしたものです。
文字列そのものはある程度データ化が可能ですが、元の版本が持つ様々な情報が欠落してしまっています。
例えば単純なレイアウトを始め、ページ(第何葉の左右(表裏))・行割の情報(縦書き等)・割注・等のマークアップ情報 が欠落してしまっているのが了解されるでしょう。
仮にテキストデータをレイアウトに似せて書いてみましょう。
【故言諸衆】若夫有道之士必禮必知然後其智能可盡【可盡
得而用也】解在乎勝書之說周公可謂能聴矣齊桓公之
見小臣稷魏文侯之見田子方也皆可謂能禮士矣
【能禮士故曰得士商紂不能禮士故失太公以滅亡也】
務本
六曰嘗試觀上古記三王之佐其名無不榮者其實
無不安者功大也【上古記上世古書也名者爵位名也實者功實也】詩云有
晻淒淒興雲祁祁雨我公田遂及我私【詩小雅大田之三章也晻
陰雨也陰陽和時雨祁祁然不暴疾也古者井田十一而税公田在中私田在外民有禮讓之心故願先
公田而及私也】三王之佐皆能以公及其私矣俗主之佐其
呂氏春秋卷十三 十一
欲名實也與三王之佐同而其名無不辱者其實無
不危者無公故也皆患其身不貴於國也而不患其
主之不貴於天下也皆患其家之不富也而不患其
國之不大也此所以欲榮而愈辱欲安而益【一作愈】危
安危榮辱之本在於主主之本在於宗廟宗廟之本
在於民民之治亂在於有司【有司於周禮為太宰掌建國之六典以佐王治
邦國以治官府以紀萬民此之謂也】易曰復自道何其咎吉【乾下巽上小畜初九
復自道何其咎吉乾爲天天道轉運爲乾初得其位旣天行周匝復始故曰復自道也復自進退又何咎
乎動而無咎故吉也】以言本無異則動卒有喜【乾動反其本終復始無有異故
卒有喜也】今處官則荒亂臨射則貪得【欲多】列近則持諫【列位】
こうすると見た目はそれらしくできます。しかし、バイナリエディタで見ると色々と問題が見えてきます。
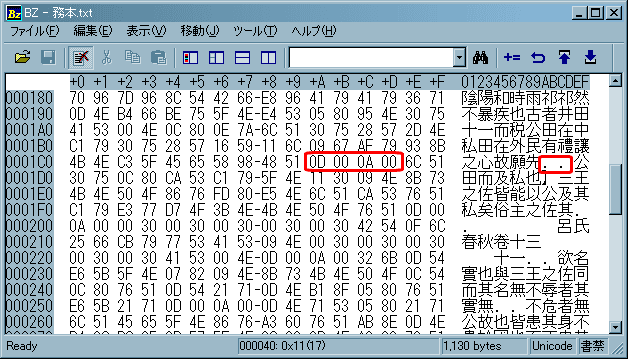
BZで上記データをUnicode(UCS-2でエンコードしたもの)保存したテキストファイルを開いた所
このデータは、行の変わり目を改行命令で再現しています。そのため、前行と次行との間はデータ的には連続しません。
例えば上から9~10行目は「故願先【改行 byte列0D000A00】公田」となっていますから、→「先公」というキーワードを指定した場合、この部分は検索にヒットしないのです。
ここでは、「行末から行頭に跨る語彙」に関わる情報の欠落が発生してしまっていることになります。結局の所、このようなデータでは、一文字の検索程度にしか使えないのです。
上記の通り、プレーンテキストは一次元の産物でしかありません。従って構造化されたデータを再現する事は苦手なのです。
むしろ、変に元データの構造にこだわってそれを再現しようとすると、テキストのテキストデータの利点を損なうことにもなりかねません(改行データ を乱発することで、文字列の繋がりが阻害されてしまうのは今挙げたとおりです。)。
全ての情報をプレーンテキストのみで包括する事は難しいのです。従って電子テキストを作成するに当たっては、どの情報を反映するかというデータの取捨選択が必要となってきます(本文文字列のつながりを重視するかレイアウトや書き込み情報を重視するか。)。
もっとも最近では、プレーンテキストの特徴を保ちつつ、テキストの構造や情報を埋め込むために、マークアップと呼ばれる手法を利用することが盛んになってきました。
マークアップでよく知られているのが、htmlです。またxmlもよく使われるようになってきています。
これについては別途紹介しましょう。
電子テキストの流動性
インターネット上で閲覧可能なテキストデータはあまたありますが、内容はと言えばピンからキリまでであり質的に不揃いと言えるのが現状で、これは永遠に代わる事は無いでしょう。しかも、この「質」というのがくせ者で、この場合の「質」とは「閲覧する読者にとって」という意味合いです。従って、Aにとってはゴミデータであっても、Bにとっては宝の山という事も十分にあり得ます。
前に改編と公開の容易さについて書きましたが、この特徴故に公開されている電子テキストは元データを追跡する事を難しくさせます。
引用元(改造元)を明示してあればよいのですが、それを明示しないWebサイトも多いのも事実ですし、著作権無視の無断引用も多 く見られます。
この流動性故に紙に印刷されて固定化した文字データに比し、信頼性に欠けるのは否めません。
そこで、公開する側のテキストに対する責任(信頼度を高めるための)が生じてくるわけですが、当然義務的なものではありません。そのため間違ったデータが流れる可能性もあるわけです。そこで、電子テキストを二次利用したい倍には、本体の系統とそれが「使えるか否か」を閲覧者が判断する必要が求められます。
前のページでは、電子テキストの特徴を挙げましたが、何もプラス方面の特徴ばかりではありません。電子テキストであるが故の限界というのも多く指摘する事が出来ます。
ここでは、それについて書いてみました。